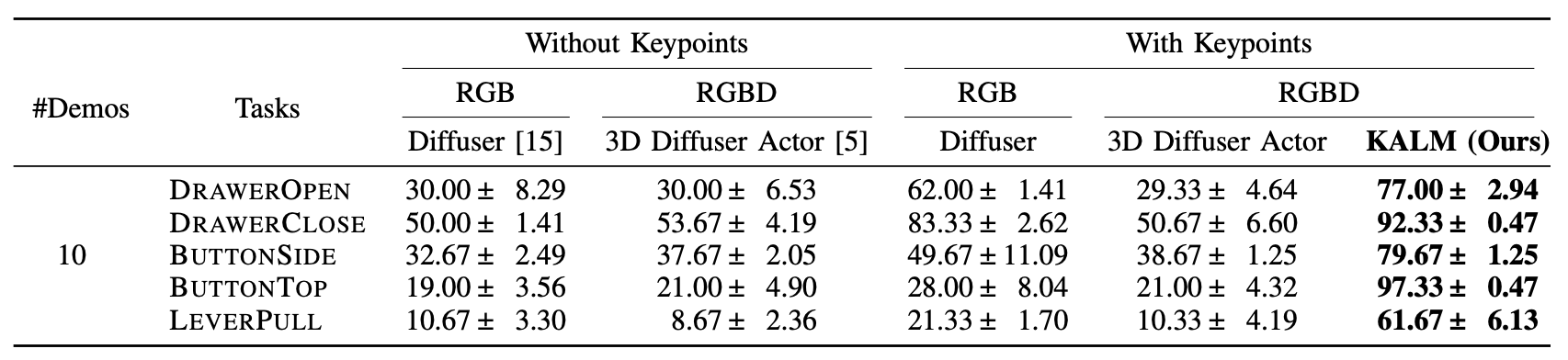
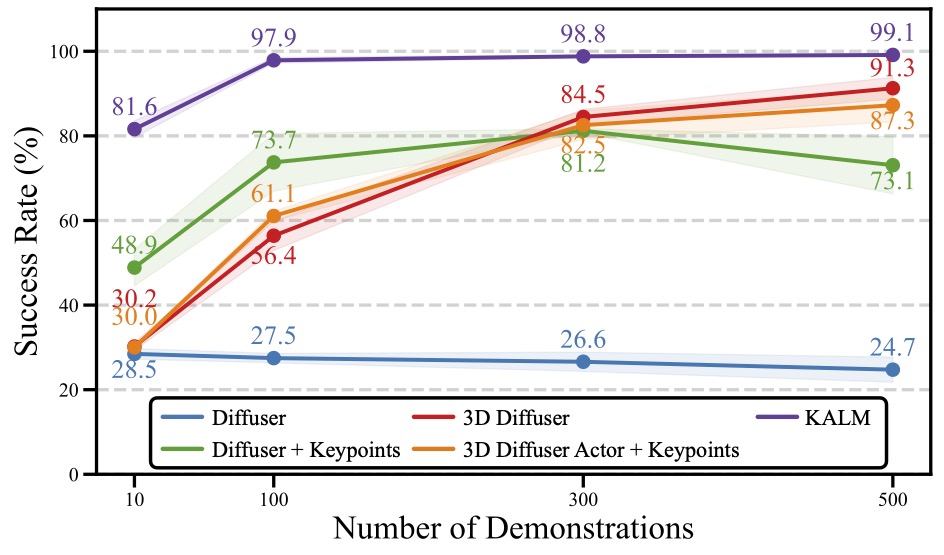
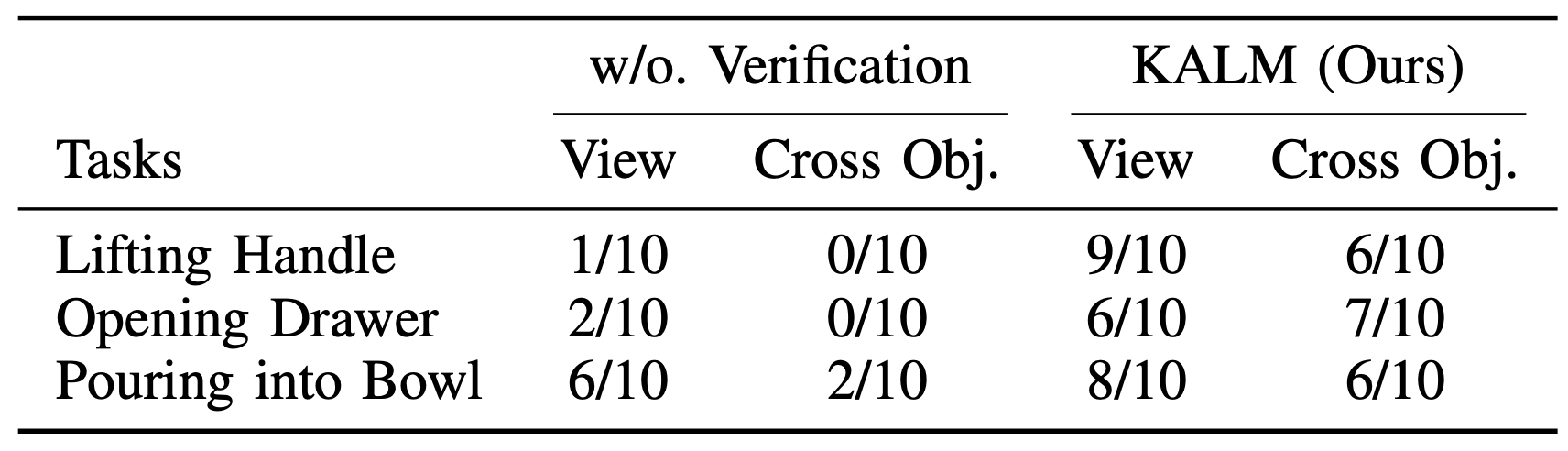
KALM Overview
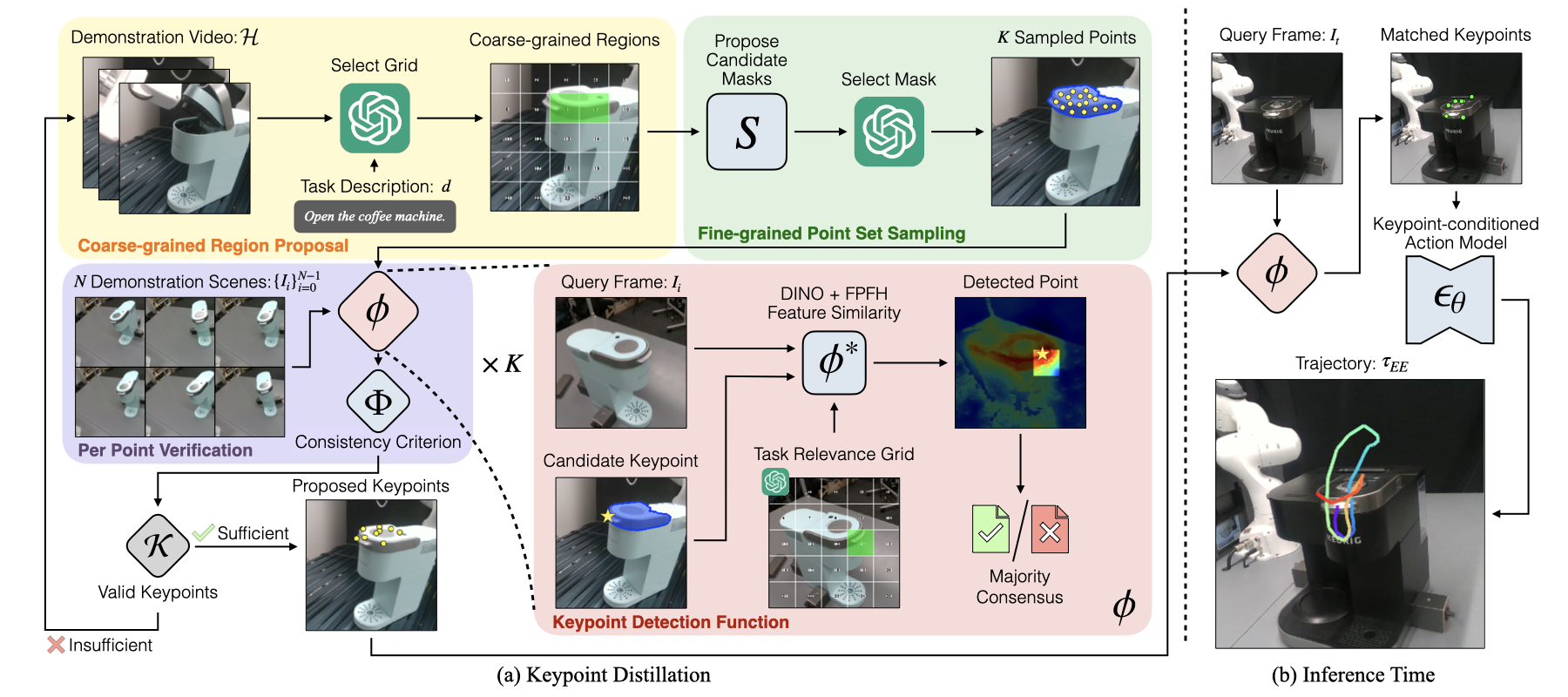
(a) Given a demonstration video and a task description, we prompt a VLM to generate a coarse-grained region proposal , which is refined into a fine-grained point set via image segmentation models and VLMs. We use a keypoint detection function \(\phi\) to identify keypoint correspondences across a handful of demonstration trajectories. The final keypoints set is selected based on correspondence consistency verification. These keypoints are used for training a keypoint-conditioned action model. (b) Given a new scene, the keypoint detection function \(\phi\) localizes the distilled keypoints. The learned keypoint-conditioned action prediction model generates an object-relative end-effector trajectory based on the keypoint positions and features.